MoDe: Controlling Classifier Bias
Get the code here.
MoDe
Moment Decorrelation (MoDe) is a tool that can enforce decorrelation between some nuisance parameter (or protected attribute in ML fairness lingo) and the response of some model with gradient-based optimization (a neural network for example.) It can force trained models to have the same response across different values of the protected attribute but it can also go beyond simple decorrelation. For example, MoDe can constrain the response function to be linear or quadratic in the protected attribute. This can increase performance tremendously if the independence constraint is not necessary but instead one only cares about the “smoothness” of the dependence of the response on the protected attribute (which is a weaker constraint).
For more details please see our article at 2010.09745. (Please use INSPIRE-HEP for citations.)
An implementation is available in each of TensorFlow and PyTorch. The notebooks in examples/ illustrate how MoDe is used and show how one can obtain different response functions on a toy example and on a W-tagging dataset.
Installation
pip install modeloss
The PyTorch implementation requires PyTorch 1.6.0 or newer. The TensorFlow implementation requires TensorFlow 2.2.0 or newer.
Usage
For PyTorch:
from modeloss.pytorch import MoDeLoss
flatness_loss = MoDeLoss(order=0)
loss = lambda pred,target,m,weights: lambd * flatness_loss(pred,target,m,weights)+\
classification_loss(pred,target,weights)
For TensorFlow, replace modeloss.pytorch above with modeloss.tf.
Example
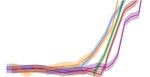
This is a toy example (located in examples/ToyExampleTF.ipynb) in which the signal (samples with label 1) is localized near the value 0.2 of the protected attribute m. While backgrounds (samples with label 0) are uniform in this feature, we note that this bias is introduced into any naive classifer. Indeed, we see that an unconstrained classifier (in the sense that it has no additional fairness regularization) has a large false positive rate for backgrounds near m = 0.2. Here we show how different MoDe regularizations (MoDe[n]) mitigate this bias by flattening the false positive rate as a function of the protected attribute m into its n’th legendre decomposition (where n is the highest moment allowed; 0 is flat, 1 is linear, etc) .

Left: The false positive rate versus mass (m) for various models at signal efficiencies (or true positive rates (TPR)) ε = 80, 50, 20% (each set of 3 identically colored and stylized lines correspond to the same model but with selection thresholds chosen to achieve the 3 desired TPRs). The bottom panel
shows that MoDe[1] and MoDe[2] completely overlap with the m-agnostic model for this simple
example, which is expected because the optimal classifier here has linear dependence on mass (see paper). Right: ROC curves for MoDe[0], MoDe[1], and MoDe[2] compared to the m-agnostic
model and a model with unconstrained mass dependence. As in the left panel, we see that MoDe[1],
MoDe[2], and the m-agnostic ROC curves are nearly identical because the optimal classifier has
linear mass dependence in this simple example.
For more details see 2010.09745.
Publications
Controlling Classifier Bias with Moment Decomposition: A Method to Enhance Searches for Resonances